On Computational Interestingness
“In the real world it is more important that a proposition be interesting than that it be true. The importance of truth is that it adds to interest.” — Alfred North Whitehead, Process and Reality (1929)
The Problem
There is a phrase, attributed to Isaac Asimov1, that captures something important about how discovery works: “The most exciting phrase to hear in science, the one that announces new discoveries, is not ‘Eureka!’ but ‘That’s funny…’” What matters is the moment before discovery: something doesn’t fit. An anomaly, an unexpected spike, a pattern that shouldn’t be there. Before a researcher or analyst can find anything, something must first strike them as worth investigating.
On April 8, 1982, Dan Shechtman, a scientist visiting the National Bureau of Standards in Washington, aimed an electron beam at a rapidly cooled aluminum-manganese alloy. The diffraction pattern that appeared on his screen showed tenfold rotational symmetry, something that, according to more than 100 years of crystallography, could not exist. In his lab notebook, next to sample number 1725, he wrote: “(10 Fold ???)”.2

We have centuries of epistemology devoted to the question of when a belief counts as knowledge and comparatively little devoted to the prior question of which beliefs are worth forming in the first place. The philosophy of science spent most of the twentieth century on the context of justification (how we test theories) while explicitly banishing the context of discovery (how we generate them) as a matter for psychology, not philosophy.
In this essay, I will trace the concept of interestingness across many disciplines that have tried to pin it down, and argue that there is a convergence. Two major approaches to formalizing interestingness are meeting. The first, rooted in statistics and information theory, decomposes interestingness into computable properties: novelty, surprise, coverage, utility, and so on. The second, enabled by foundation models (FMs), treats interestingness as a human judgment that can be approximated by systems trained on the vast record of what humans have found worth writing about.
Can formal measures, calibrated by the internalized priors of foundation models, give us a working account of interestingness? As scientific research itself becomes increasingly automated, the question is not merely academic, and it is, of course, a very interesting one.
The Psychology of Interest
The scientific study of interestingness begins, like most things in experimental psychology, with arousal. Daniel Berlyne’s Conflict, Arousal, and Curiosity (1960) provided the first systematic framework. Berlyne proposed that stimuli possess what he called collative variables: properties that require comparing incoming information against expectations or memory. He identified four:
- novelty (it has not been encountered before),
- complexity (many distinct elements appear in irregular arrangements),
- uncertainty (competing expectations about what comes next),
- conflict (simultaneous incompatible responses).
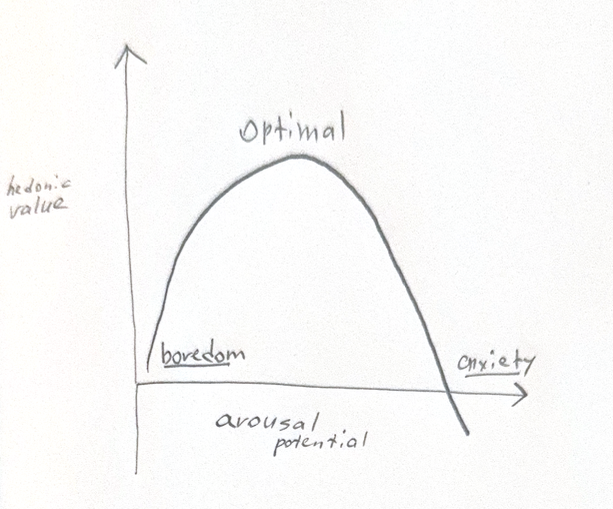
Berlyne argued that collative variables modulate arousal, and that arousal relates to hedonic value along an inverted-U curve — the Wundt curve, named after the founder of experimental psychology who first described the relationship between stimulus intensity and pleasantness. Berlyne’s move was to replace the x-axis (raw sensory intensity) with arousal potential driven by collative variables. Too little arousal produces boredom, too much produces anxiety. Interest lives at the peak. It is also where most exploratory effort goes, seeking what Berlyne distinguished as either diversive exploration (broad search driven by understimulation) or specific exploration (focused investigation of a particular anomaly).
George Loewenstein’s information-gap theory (1994) recast curiosity (but not interest!) as a drive state analogous to hunger. Curiosity arises when attention is drawn to a gap in one’s knowledge, but crucially, a small amount of information about the gap acts as a “priming dose” that increases rather than satisfies the drive. We become more curious about something the more we learn about it. Loewenstein noted, however, that satisfying curiosity is often disappointing. The gap, not the answer, is where the interest lives. It explains why experts remain fascinated by their domains: expertise doesn’t close the gap but makes its contours more visible.
Paul Silvia, in his appraisal theory of interest (2005, 2006), argued that interest is an emotion with a two-factor structure. The first factor is a novelty-complexity appraisal: is this stimulus new, complex, or unexpected? The second is a coping-potential appraisal: do I have the resources (the background knowledge, the skills) to engage with it? High scores on both produce interest. High novelty with low coping potential produces confusion. Low novelty produces boredom regardless of coping potential.
This two-factor model explains why interestingness is observer-relative. The same mathematical proof can be boring to a Grigori Perelman (low novelty), confusing to a first-year undergraduate (low coping), and interesting to an advanced graduate student (high on both).
The same anomalous diffraction pattern produced completely different responses depending on the observer’s coping potential. Shechtman himself experienced interest: high novelty met by high coping. Linus Pauling, a double Nobel laureate with enormous expertise, experienced hostility: “There is no such thing as quasicrystals, only quasi-scientists.” And the observers who had seen similar anomalies in earlier decades experienced nothing at all as they explained the patterns away as twinning or discarded the samples. Same stimulus, three responses: interest, hostility, invisibility.
The insight is that interestingness is not a property of stimuli. It is a property of the relationship between a stimulus, an observer, and a context. Any account that treats interestingness as intrinsic to the data will be, at best, a useful approximation.
The Sociology of Interesting
In 1971, the sociologist Murray Davis published an essay titled “That’s Interesting!”. According to Davis, a theory is considered great not because it is true but because it is interesting. Theories that are true but not interesting are acknowledged and forgotten. Theories that are interesting but not entirely true reshape fields. Davis proposed a structural analysis of what makes a proposition interesting. The answer, he argued, is that interesting propositions deny an assumption held by their audience. Non-interesting propositions, on the other hand, affirm existing assumptions.
Where the audience takes X for granted, the scientist shows that what seems to be X is in fact non-X. Davis catalogued twelve structural types (called The Index of the Interesting):
- what seems to be a local phenomenon is in reality a general phenomenon;
- what seems to be a bad effect is actually a good one;
- what seems to be an independent variable is actually a dependent one;
and so on.3
The underlying mechanism, he argued, is always the same: assumption-violation.
Davis drew a further consequence from this: whether a proposition is interesting depends entirely on who is hearing it. A finding that overturns the assumptions of one community may be perfectly obvious to another. If the audience already believes non-X, telling them “what seems to be X is actually non-X” is boring; it confirms what they know. If the audience doesn’t even hold X as an assumption, the proposition is irrelevant. Interestingness, again, occupies a middle zone between the obvious and the absurd, and that zone shifts with the audience.4
Shechtman’s quasicrystal was a proposition that denied a foundational assumption: all ordered matter is periodic. For the crystallographic community, this was not just interesting, it was offensive. Shechtman’s first paper was rejected by the Journal of Applied Physics. The finding sat just past the edge of that zone: too far from assumptions to be interesting, close enough to be threatening.
Davis was writing about sociology, but his analysis applies wherever theories meet audiences. It is, in a sense, a theory of why the same fact can have completely different epistemic fates in different communities, and it makes the “for whom?” question not an inconvenient complication but the central problem of any measure of interestingness.
Anomaly and The Prepared Mind
“In the fields of observation, chance favors only the prepared mind” — Louis Pasteur, Lecture, University of Lille, 7 December 1854.
In The Structure of Scientific Revolutions (1962), Thomas Kuhn argued that science does not progress by steady accumulation. It alternates between long periods of conservative “normal science” (working within a shared paradigm) and brief, disruptive revolutions that replace one paradigm with another. The hinge between these two modes is the anomaly: the observation that violates the paradigm’s expectations.
Kuhn’s insight is that anomalies only become visible against a background of precise expectations. The better the paradigm, the more accurately it predicts, the more sharply anomalies stand out. A vague theory generates no surprises because it is compatible with almost anything. A precise theory makes the unexpected unmistakable. This is why mature sciences produce revolutions: you need a well-developed world model before violations of that model can register as significant.
The crystallographic restriction theorem established that periodic lattices can possess only two-, three-, four-, or six-fold rotational symmetries. For seventy years, hundreds of thousands of crystals had been studied, and every one obeyed the theorem. The paradigm’s precision is what made Shechtman’s tenfold pattern so unmistakable: a vaguer theory of crystal structure would never have generated those three question marks.
Kuhn’s normal science, activity that occupies most scientists most of the time, is not directed at producing novelty. Its aim is to extend the paradigm’s reach, increase its precision, and articulate it for new domains. Kuhn compared it to solving puzzles: the outcome is largely anticipated, and the challenge lies in how to achieve it, not in what will be found. He noted that the results of normal research are often predictable and themselves uninteresting; what drives scientists is the ingenuity required to bring the paradigm and nature into closer agreement.
But the paradigm’s very precision creates the conditions for its own disruption. When a normal problem resists the reiterated efforts of the community’s members, when equipment designed for paradigm-guided research fails to behave as expected, the result is anomaly. At first, anomalies are accommodated: treated as instrumentation errors, set aside as problems for future work, or explained away by ad hoc modifications. Only when they accumulate, resist resolution, and strike at the paradigm’s foundations does a crisis develop. Scientists begin questioning fundamentals. Multiple competing approaches proliferate. The field, Kuhn observed, begins to resemble its pre-paradigmatic state.
And in fact, puzzling diffraction patterns had been observed before 1982, but until the concept of a quasicrystal existed, they were explained away as twinning artifacts or simply set aside. Meanwhile, crystallographer Alan Mackay had independently predicted in 1981–82, using Penrose tilings, that fivefold diffraction patterns were theoretically possible. He warned colleagues to watch for them: “If we thought them impossible, they might go by us unnoticed and unrecognized.” Shechtman, unaware of Mackay’s work, noticed anyway. Two prepared minds, Pasteur’s principle in action.
This anticipates a computational formalization we have not yet reached: the anomaly is interesting not because it is random (noise is incompressible and therefore uninformative) but because it is a structured violation, one that hints the model needs revision in a specific direction. The anomaly carries information about a better model. Soon we will see how Schmidhuber formalizes it as compression progress.
Measuring Interestingness
While psychologists and sociologists were analyzing interestingness as a human experience, the data mining community had long been trying to compute it. The challenge was practical: knowledge-discovery systems generate enormous numbers of patterns (back in the 1990s it was association rules, clusters, classification rules, or statistical summaries) and most of them are trivially true or already known. Analysts needed some way to rank patterns by their value. They needed a measure of interestingness.
The earliest account came from Frawley, Piatetsky-Shapiro, and Matheus (1992),5 who defined a discovered pattern as interesting if it was:
- novel (previously unknown),
- useful (when it can help achieve a goal of the system or the user),
- non-trivial to compute.
Rule/pattern interestingness has both objective (data-driven) and subjective (user-driven) aspects. By the late 1990s, several groups had formalized the two main subjective signals. Unexpectedness (does the rule surprise the user?) and actionability (can the user act on it?) emerged as the key dimensions that separate interesting rules from merely valid ones (Silberschatz & Tuzhilin, 1996; Liu et al., 1997). Liu et al. proposed a specification language for users to encode their “general impressions” about a domain, against which discovered rules could be matched, an early attempt to make the subjective component of interestingness computationally tractable.
Freitas (1999) identified practical features like class imbalance and attribute costs, while McGarry (2005) noted the persistent gap between purely objective formal measures and the deeply subjective judgments they were meant to approximate.
The most comprehensive taxonomy came from Geng and Hamilton (2006), who surveyed the full landscape of interestingness measures used in data mining and proposed formal criteria, each one with a set of measures:
- conciseness (the goal is to find a minimum set of patterns),
- coverage (a pattern covers a large subset of data),
- reliability (predictions are highly accurate),
- peculiarity (far away from discovered patterns),
- diversity (pattern covers diverse elements),
- novelty (pattern was unknown before),
- surprisingness6 (contradicts existing expectations),
- utility (contributes to reaching a goal),
- actionability (enables decision making about future actions).
The criteria were divided into three classifications. Two are already familiar to us: subjective (user model is needed, surprisingness and novelty go into this category), objective (only raw data is needed). The third, semantics-based (utility and actionability), was new.
The authors also compared thirty-eight (!) distinct mathematical measures (lift, conviction, J-measure, chi-square, information gain, added value, odds ratio, Yule’s Q, and many others) and showed that each implicitly weights a different subset of the nine criteria listed above.
Several groups noted that interactive systems with user feedback could narrow the gap, a precursor to what would later re-emerge with foundation models.
More recent work has continued the decomposition. Chanson et al. (2024) proposed six dimensions specifically for exploratory data analysis (peculiarity, novelty, relevance, surprise, diversity, and presentation) emphasizing that how an insight is displayed affects whether it registers as interesting.
Consider the quasicrystal diffraction pattern against the formal criteria. It scores maximally on novelty (never observed), surprise (contradicts a theorem), peculiarity (unique among hundreds of thousands of crystals), and reliability (reproducible, not an artifact). By any objective interestingness measure, it should have been flagged immediately. Yet it was rejected. The formal measures cannot capture whether an observer’s background model has room for the finding. A pattern can be objectively surprising and subjectively unacceptable. The gap between the two is exactly the gap that formal measures cannot close.
The fundamental tension in this tradition is between formalizability and fidelity. Any individual criterion (say, statistical deviation from expectation) can be computed precisely, but it captures only a fraction of what humans mean by “interesting.” A formula can flag a pattern as statistically unusual, but the same formula will flag trivial patterns (every dataset contains outliers) while missing the patterns that provoke genuine intellectual excitement.
What no formula captures is the belief update, the scientist who looks at a result and thinks: that’s unexpected, and it makes me think differently about the domain.
Surprise, Curiosity and Compression
In 2005, Itti and Baldi proposed a formal Bayesian definition of surprise as the KL divergence between an observer’s posterior and prior belief distributions. Surprise, as they define it, is how much observing new data changes one’s beliefs.
This was distinct from two things people confuse with surprise:
- Shannon information, which measures how rare an event is under a model. A fair coin landing heads has the same information every time. But it’s never surprising, because it doesn’t change your belief that the coin is fair.
- Outlier detection, which flags data that has low likelihood under the single best model. But data can be a strong outlier and carry zero surprise if it’s equally unlikely under all competing models; it tells you nothing about which model is right, so your beliefs don’t move.
They tested this on eye-tracking data (people watching TV and video games). They computed “low-level” Bayesian surprise using simple visual neuron models (color, orientation, motion features), updating beliefs about which statistical model best describes each image patch over time. Then they compared: do humans look at surprising locations more than at merely salient, high-contrast, or high-entropy ones?
Yes — and by a wide margin. Surprise outperforms all other metrics. A continuously blinking light is a perpetual outlier (high saliency) but quickly becomes unsurprising because your model adapts to it. Random pixel noise excites all detectors (high entropy, high information) but is immediately unsurprising because it doesn’t shift beliefs toward any particular model. Only structured violations (things that really force genuine model revision) sustain surprise.
In 2009, Jürgen Schmidhuber proposed a formalization of interestingness.7 He argued that interestingness is the first derivative of compressibility. A dataset is beautiful if the observer’s internal model can compress it (= represent more compactly). A dataset is interesting if engaging with it produces compression progress, so the observer’s compressor is actively improving, discovering new regularities that allow shorter descriptions. A discovery is a very large compression breakthrough.
The framework maps Berlyne’s inverted-U: boredom on the left, confusion on the right, fascination at the peak where compression is progressing fastest.
Schmidhuber claimed this single principle unifies novelty, surprise, curiosity, creativity, humor, art, and science. Curiosity is the drive to seek data that maximizes compression progress. Creativity is the generation of data whose structure is just beyond the current compressor’s reach. A joke is funny because the punchline reveals a compressed reinterpretation of the setup, and the compression progress is sudden and dramatic. In a way, a scientific discovery is interesting for the same reason.
Schmidhuber’s framework bridges the psychology of curiosity and the mathematics of information theory. Berlyne’s collative variables are properties that signal compressible structure the observer has not yet captured. Silvia’s coping potential is the observer’s current compression capacity. Loewenstein’s priming dose (the partial information that increases rather than satisfies curiosity) is exactly partial compression: enough structure revealed to make further compression look achievable.
Oudeyer and Kaplan (2007) taxonomized the computational approaches to intrinsic motivation (prediction error, learning progress, information gain, competence progress) and argued that learning progress (related to Schmidhuber’s compression progress) is the most robust signal, because it automatically ignores both already-learned regularities and unlearnable noise. Pathak et al. (2017) built the Intrinsic Curiosity Module (ICM), which operationalized curiosity as prediction error in a learned feature space. Their agents explored video-game environments without any external reward, driven entirely by the signal of their own surprise. The ICM became the practical ancestor of a generation of curiosity-driven RL systems.
The framework had gaps. Agents driven by prediction error became captivated by stochastic elements. This was the noisy-TV problem (Burda et al., 2018). It revealed that raw prediction error is not compression progress: a noisy TV generates perpetual error precisely because it is incompressible. The problem was one of the motivations for turning to foundation models: systems that, having absorbed human priors about what constitutes meaningful structure, would not mistake static for fascination.
Interestingness is still observer-relative. How can we approach simulating subjective human interestingness? Wouldn’t it be too naive just to ask a large enough language model: is this interesting?
Now Come the Foundation Models
Several research groups independently arrived at the same idea: large language models already encode a model of human interestingness — they inherit a prior over what humans find worth discussing. The experiments that followed can be read as a progression: FM as exploration filter, FM as scientific evaluator, and finally FM as a formalized belief-updating system. Each step placed more weight on the FM’s judgment and asked harder questions about what that judgment actually is.
I will start with OMNI (Zhang, Lehman, Stanley, and Clune, 2024), which used foundation models as a “Model of Interestingness” to guide open-ended reinforcement learning.8 OMNI’s insight was that the inability to quantify which tasks are not just learnable but interesting (the longstanding bottleneck in open-ended learning) could be dissolved by delegating the judgment to a language model. The system filtered candidate tasks through two screens: a learning-progress filter (is this achievable given the agent’s current skill level?) and a language model interestingness filter (is this worthwhile and novel?). The combination outperformed systems using either filter alone.
OMNI’s two-filter design combines Schmidhuber’s compression progress (the learning-progress filter) with a human-judgment proxy (the FM filter). The authors find that FMs (GPT-4 at the time) possess the capacity to integrate multiple aspects of interestingness.
OMNI-EPIC (Faldor et al., 2025) extended this approach by having FMs generate code specifying entire RL environments, achieving what the authors called “Darwin Completeness” — the potential to create any possible learning environment, with interestingness judged at every step, demonstrating that FM interestingness judgments scale from evaluating individual tasks to generating entire worlds.
Intelligent Go-Explore (Lu, Hu, and Clune, 2024) replaced the handcrafted heuristics in a hard-exploration RL algorithm with foundation-model judgments. The FM determined which discovered states to archive and explore from, providing what the authors described as “a human-like ability to instinctively identify how interesting or promising any new state is.” This showed that FM judgment could replace all handcrafted exploration heuristics, not just supplement one.
Where OMNI and IGE used FM judgment to guide what to explore, the next wave applied it to what to investigate, moving from reinforcement learning environments to scientific hypothesis generation.
The AI Scientist (Lu et al., 2024) pushed the concept into scientific discovery itself, building a system that generates research ideas, runs experiments, writes papers, and evaluates them through simulated peer review. Interestingness here was operationalized as what would survive the review process (a social proxy, in the spirit of Davis). Computationally, it was extracted from an FM with a prompt that separates Interestingness, Feasibility, and Novelty as independent ratings from 1 to 10.
InterFeat (Ofer, Linial, and Shahaf, 2025) decomposed FM-assessed interestingness into three scored dimensions (novelty, utility, and plausibility) and applied it to biomedical hypothesis generation, where 40–53% of the system’s top candidates were validated as interesting by physicians. They also combined LLMs with Knowledge Graphs (“If a feature x is already directly connected to the disease y in the KG (with sufficient evidence), we mark it as known (i.e., not novel) and exclude it.”).
A separate line of work probed what FM-assessed interestingness trades off against. EUREKA (Sato, 2025) introduced and evaluated classifiers that prioritize interesting features over accurate ones, arguing that a model predicting room occupancy from humidity (surprising, ~85% accurate) is more scientifically interesting than one predicting it from CO₂ levels (obvious, ~99% accurate).
The most direct test of whether FM interestingness tracks human judgment came from Mishra et al. (2025), who compared LLM ratings against both crowd workers and International Mathematical Olympiad competitors. They discovered that LLMs broadly agreed with humans on what is interesting but failed to capture the distribution of judgments and only weakly correlated with why humans found problems interesting, suggesting that FMs approximate the surface of human interestingness without fully modeling its structure.
AutoDiscovery (Agarwal et al., 2025) pushed furthest toward resolving this. Rather than simply asking an FM to rate interestingness, the system asks an LLM to predict experimental outcomes before seeing results, thus establishing a prior. It then presents the actual results and measures how much the LLM’s beliefs shift — Bayesian surprise, computed over an FM’s probability distribution rather than over a statistical model of visual features. This is Itti and Baldi’s framework, but where Itti and Baldi used simple neuron models as the belief-holder, AutoDiscovery uses a language model trained on the scientific literature. The observer whose surprise is being measured is no longer a low-level perceptual system but something closer to a scientist’s expectations. The open problems remain: the LLM’s “prior” is a single prompted prediction, not a calibrated distribution; it reflects the training corpus, not any particular audience; and the “belief update” is prompt-level conditioning, not genuine learning. But the formalism marks a step from asking “is this interesting?” to asking “how much does this change what you expected?”
What these experiments collectively show is not convergence on a solution but convergence on the same unsolved problem: interestingness is always relative to an observer, and no system yet knows whose observer it is approximating.
Interesting to Whom?
The history traced above reveals two traditions converging on the same problem from opposite directions.
The first, the formal decomposition, begins with Frawley et al. in 1992 and runs through Geng and Hamilton’s nine criteria, Schmidhuber’s compression progress, Bayesian Surprise and many mathematical measures catalogued in the data mining literature. Each measure is defined, computable, and comparable. No measure captures the full human judgment of interestingness, though. The measures work best where the problem is well-defined and the user’s background knowledge can be modeled explicitly, but this is exactly where the most interesting discoveries are least likely to occur.
The second, FM-internalized human judgment, begins with OMNI in 2024.9 The FM has absorbed, through training, something like the integrated judgment that a human expert brings to bear: not just statistical deviation but something closer to taste. But the judgment is opaque. We cannot easily decompose it into interpretable components or calibrate it against specific domains, and we still cannot answer the question Davis showed is fundamental: interesting to whom?
FMs appear to have learned something like Silvia’s appraisal structure: they can assess both novelty and whether a finding is learnable. They respond to surprises more than to random noise — Schmidhuber’s compression progress by another name. And they are sensitive to conciseness, coverage, peculiarity, and the rest of Geng and Hamilton’s criteria, without being explicitly trained on any of them. This convergence is either evidence that interestingness leaves recoverable traces in human text, or it reflects the rhetorical surface of interestingness rather than its cognitive substance. Mishra et al.’s distribution mismatch points toward the latter.
The path forward is not to choose between formal measures and FM judgment but to find better combinations of both. The criteria are computable; what they lack is the observer. FMs add something those criteria never had: a proxy for exactly the kind of judgment the formal tradition could not encode. The experiments so far are early probes: AutoDiscovery, OMNI, InterFeat each test one possible combination. What a more complete framework looks like — how observer priors get encoded, how the interestingness signal updates over time, whose judgment gets approximated — is the open territory the next section maps.
Open Questions
Context and Audience. Observer-dependence implies that any operational system must encode who is asking. A discovery system that cannot represent its user’s knowledge, assumptions, and goals will produce results interesting to no one in particular. The open problem is representational: how do you encode an audience’s paradigm well enough that violations of it can be detected?10 Knowledge graphs, interaction histories, general impressions, tuned language models, and Claude/OpenClaw skills are partial answers. None yet approaches what a human expert brings to “that’s funny.”
Continuous Exploration and Interestingness Over Time. An interesting finding changes the observer: it updates the model, shifts expectations, opens new gaps. The next finding must be evaluated against the updated observer, not the original. Current systems mostly lack this loop: FMs rate candidates independently, formal measures rarely revise their priors between evaluations. The result is a system that can spot interesting findings but cannot explore, cannot follow a thread the way a scientist follows an anomaly from observation through hypothesis to the next experiment.
Self-improving agentic systems are a path forward: a scientist whose own model has been updated — via RL-based weight updates or self-modifying agent code — by a discovery can steer himself toward the new frontier, delegating the search while retaining the evolving sense of what counts as interesting. At the same time, interestingness itself is not a snapshot: a discovery can make previously uninteresting datasets newly relevant.
Recently, Herrmann and Schmidhuber (2026) provided a formal account of why this loop matters. They argue for interestingness understood as “a prospective heuristic that predicts future learning progress”, not a score assigned after engagement, but a signal evaluated before it. They also prove that past compression progress predicts future compression progress, but only if that progress is recent: the probability of a future breakthrough decays exponentially with the time elapsed since the last one.
Presentation. Chanson et al. were right to include presentation among their dimensions. The same finding can register as fascinating or forgettable depending on how it is surfaced: a table of p-values buries what a well-chosen visualization reveals. Neither tradition has seriously engaged with rhetoric, information design, or perceptual psychology as components of interestingness.
The Alignment Problem of Interestingness. There is a deeper alignment problem here that goes beyond gaming. RLHF trains models to match human approval, which may systematically suppress the genuinely novel: a hypothesis that overturns an assumption will be uncomfortable before it is accepted. An aligned model optimized for human preference may be structurally biased toward the interesting-but-safe over the interesting-but-threatening. Can a sufficiently aligned model produce a hypothesis its audience does not yet want to hear?
The Hivemind Problem. The question of whose interestingness FMs approximate becomes harder when different models approximate the same thing. Jiang et al. (2025) document what they call the Artificial Hivemind: across open-ended generation tasks, models from different labs, trained on different corpora, converge on very similar outputs. If interestingness judgments are subject to the same homogenization, using multiple FMs to cross-validate or diversify interestingness assessments may not help. The system would be checking one averaged prior against another copy of itself. The zone of productive interestingness may have already been narrowed by training before any particular audience’s assumptions are encoded.
Pathological Interestingness. If the FM inherits an averaged human interestingness function, it inherits the failure modes too. Clickbait is optimized for Loewenstein’s information gap. Conspiracy theories score high on Davis’s assumption-violation and Berlyne’s collative variables. Pseudoscience can produce enormous compression progress against a naive model. If interestingness can be formalized, it can be gamed.
Buying Interestingness. In On the Measure of Intelligence (2019), François Chollet argued that intelligence is not a fixed property of a system but a measure of skill-acquisition efficiency relative to the system’s priors, and that benchmarks ignoring this relativity measure memorization, not generalization. The parallel runs deeper than structure: just as Chollet warned that skill can be “bought” with unlimited training data in a way that masks genuine generalization, an FM’s interestingness judgment may be crystallized taste rather than fluid recognition — impressive on cases well-represented in its training corpus, unreliable precisely where it matters most.
Abductional Jump. Abduction is the creative leap from anomaly to hypothesis: it postulates something that isn’t in the data yet. Zahavy (2026) argues that LLMs face fundamental challenges here: the abductive jump requires embodied simulation that current systems cannot perform. A measure of interestingness that can only flag the statistically unusual will systematically miss the findings that matter most — the ones where the anomaly is clear but the hypothesis doesn’t exist yet. In 1982, no algorithm could have flagged sample 1725 as interesting in the sense that mattered — not “this deviates from expectation” but “this requires a new concept.” That gap is still open.11
In 1992, a decade after Shechtman’s three question marks, the International Union of Crystallography rewrote its definition of a crystal, reducing it from “a periodic arrangement of atoms” to “any solid having an essentially discrete diffraction pattern.” The paradigm did not stretch to accommodate the anomaly; it was replaced. In 2011, Shechtman received the unshared Nobel Prize in Chemistry.
-
I could not trace it to his writings. The closest Asimov quote I have managed to find, and one I can appreciate as a Russian speaker, is from Fantastic Voyage II: Destination Brain (1987), pp. 276–277: a character says: “My poor old father used to say: ‘The most frightening phrase in the Russian language is “That’s odd.”’” See also: stevenac.net/asimov/Bibliography.htm (part 1, page 8). ↩
-
The Notebook: A History of Thinking on Paper by Roland Allen is a worthwhile read on the history of notebooks. ↩
-
Full index summary: sfu.ca/~palys/interest.htm ↩
-
One can also see a connection to TRIZ, a Soviet framework for innovations that sees the challenge to a taken-for-granted assumption or apparent constraint as the engine of creativity and insight. ↩
-
They also connect “interest” and knowledge: “A pattern that is interesting (according to a user-imposed interest measure) and certain enough (again according to the user’s criteria) is called knowledge.” ↩
-
As the authors say, the difference between surprisingness and novelty is that a novel pattern is new and not contradicted by any pattern already known to the user, while a surprising pattern contradicts the user’s previous knowledge or expectations. ↩
-
In a paper called A Simple Principle Explains Essential Aspects of Subjective Beauty, Novelty, Surprise, Interestingness, Attention, Curiosity, Creativity, Art, Science, Music, Jokes. The paper synthesizes ideas developed in Schmidhuber’s earlier work (1991–2008), including a formulation related to Bayesian surprise. See also his talk at the Singularity Summit 2009. ↩
-
OMNI stands for Open-endedness via Models of human Notions of Interestingness. ↩
-
LLMs were used as both generator and judge of what counts as a worthwhile scientific direction pre-OMNI (see SCIMON by Wang, Downey, Ji, Hope (May 2023) or Semantic Anomaly Detection by Elhafsi et al. (May 2023)), but they were not using FMs to judge interestingness of scientific anomalies specifically. ↩
-
Also see: Perspectival Realism (Massimi, 2022), a current in philosophy of science that makes this precise: scientific knowledge is always historically situated, and its reliability comes not from eliminating perspective but from the productive friction between a plurality of epistemic communities. ↩
-
Incidentally, this is also a critique of Kuhn: Lakatos argued that anomalies never force theory change by themselves — a programme absorbs them until a progressive competitor emerges that accounts for the anomaly and predicts beyond it. ↩